Table of Contents
The Hadoop Distributed File System is a java based file, developed by Apache Software Foundation with the purpose of providing versatile, resilient, and clustered approach to manage files in a Big Data environment using commodity servers. HDFS used to store a large amount of data by placing them on multiple machines as there are hundreds and thousands of machines connected together. The goal is to store less number of larger files rather than the greater number of small files.
HDFS provides high reliability of data because it used to replicate data into three different copies- two are saved in one group and third one in another. HDFS is scalable in nature as it can be extended to 200 PB of storage where a single cluster contains 4500 servers, supporting billions of blocks and files.
How HDFS Works
Hadoop works on a master node which is NameNode and multiple slave nodes which are DataNodes on a commodity cluster. As all the nodes are present in the same rack in the data center, data is broken into different blocks that are distributed among different nodes for the storage. These blocks are replicated across nodes to make data available in case of a failure.
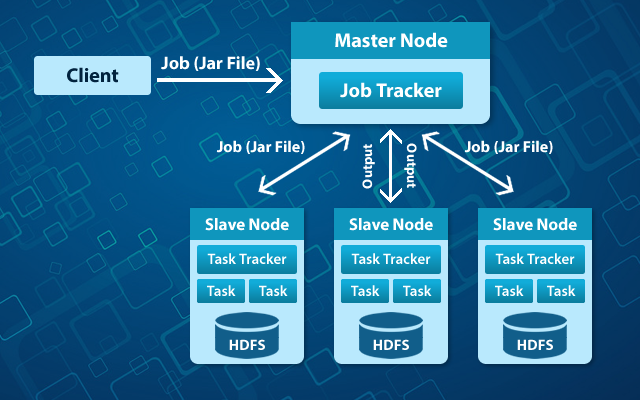
The NameNode is known as a smart node in the cluster. NameNode knows which data node contains which blocks and where data node has been placed in the clusters. The NameNode also contains the access authority which is given to files to perform read, write, create, delete and replication of various blocks between the data nodes.
The NameNode is connected with the data nodes in the loosely coupled fashion. This provides the feature of scalability in real time means it can add or delete nodes as per the requirement.
Data nodes used to communicate every time with the NameNode to check whether the certain task is completed or not. Communication between these two ensures that NameNode knows the status of each data node all the time. If one of the data nodes is not functioning properly then NameNode can assign that task to another node. To operate normally, data nodes in the same block communicate with each other. The NameNode is replicated to overcome system failure and is the most critical part of the whole system.
Data nodes are not considered to be smart, but flexible in nature and data blocks are replicated across various nodes and the NameNode is used to manage the access. To gain the maximum efficiency, replication mechanism is used and all the nodes of the cluster are placed into a rack. Rack Id is used by the NameNode to track data nodes in the cluster.
A heartbeat message is put through to ensure that the data nodes and the NameNode are still connected. When the heartbeat is no longer available, then the NameNode detach that data node from the cluster and works in the normal manner. When the heartbeat comes, data node is added back to the cluster.
Transaction log and the checksum are used to maintain the data integrity. Transaction log used to keep track of every operation and help them in auditing and rebuilding the file system, in case of an exception. Checksum validates the content in HDFS. When a user requests a file, it verifies the checksum of that content. If checksum validation matches then they can access it. If the checksum reports an error, then the file is hidden to avoid tampering.
The performance also depends on where the data is stored, so it is stored on local disk in the commodity servers. To ensure that one server failure doesn’t corrupt the whole file, data blocks are replicated in various data nodes. The degree of replication and the number of data nodes are managed at a time when the cluster is implemented.
Features of HDFS
Fault-Tolerant
HDFS is highly fault-tolerant. HDFS replicates and stores data in three different locations. So in the case of corruption or unavailability, data can be accessed from the previous location.
Scalability
Scalability means adding or subtracting the cluster from HDFS environment. Scaling is done by the two ways – vertical or horizontal.
In vertical scaling, you can add up any number of nodes to the cluster but there is some downtime.
In horizontal scaling, there is no downtime; you can add any number of nodes in the cluster in real time.
Data Availability
Data is replicated and stored on different nodes due to which data is available all the time. In case of network, node or some hardware failure, data is accessible without any trouble from a different source or from a different node.
Data Reliability
HDFS provides highly reliable data storage, as data are divided into blocks and each block is replicated in the cluster which made data reliable. If one node contains the data is down, it can be accessed from others because HDFS creates three replicas of each block. When there is no loss of data in case of failure then it is highly reliable.
Replication
Data replication is one of the unique and important features of HDFS. HDFS used to create replicas of data in the different cluster. As if one node goes down it can be accessed from other because every data blocks have three replicas created. This is why, there is no chance of data loss.
In conclusion, HDFS empowers Hadoop functionality. HDFS provides highly reliable data storage despite of any hardware failure. It is highly fault-tolerant, provides high data availability, and high scalability. So, if you want to become a Hadoop administrator, you should have a good knowledge of HDFS and other Hadoop components. Preparing for Hadoop Administrator certification? Best Big Data Online Course/s will help you prepare and pass Hadoop Administrator certification.