Hadoop HBase is based on the Google Bigtable (a distributed database used for structured data) which is written in Java. Hadoop HBase was developed by the Apache Software Foundation in 2007; it was just a prototype then.
Hadoop HBase is an open-source, multi-dimensional, column-oriented distributed database which was built on the top of the HDFS. HBase has got the scalability of HDFS with the deep analytic capabilities and the real-time data access as a key/value of MapReduce. As it is an important component of Hadoop ecosystem, it leverages the fault tolerance feature of HDFS.
HBase is designed to support large tables where scaling is done horizontally in distributed clusters. Scaling process enables HBase to store very large database tables where rows could be in billions and columns could be in millions. In Facebook Messenger entire unstructured and structured data handling is done by Hadoop HBase.
HBase provides strong consistent read and writes data functionality which makes it stand out from the other databases like RDMDS and NoSQL. HBase follows the same master/ slave architecture like HDFS where master nodes used to manage the region servers which distribute and process data tables.
Data Model of HBase
HBase stores different types of data like varying column size and different field size. Portioning and distribution of data across the cluster have been done with ease in HBase layout. HBase data model contains different logical components-
- HBASE Tables– It is the collection of rows in logical manner that are stored in different partitions called regions.
- HBASE Rows- It is an instance of data that is identified by a RowKey.
- RowKey- RowKey is used to identify every entry in HBase table by indexing.
- Columns- Attributes are stored in unlimited number in every RowKey.
- Column Family- All the rows are grouped together as column families and HFile is used to store the column.
HBASE Architecture
HBASE has no downtime in providing random reads, and it writes on the top of HDFS. Auto-Sharding is used in HBase for the distribution of tables when the numbers become too large to handle. The region is the foundational unit in HBase where horizontal scalability is done. HBASE architecture is based on master/slave architecture same as the Hadoop HDFS. Hadoop HBase architecture contains one master node known as HMaster and several slave nodes known as region servers. Each slave node (region servers) serves as a set of regions. A region server’s only job is to serve a region. Client requests HMaster to write and HMaster pass it to the corresponding region server. It can run on multiple setups but number of active master node at a time will be one.
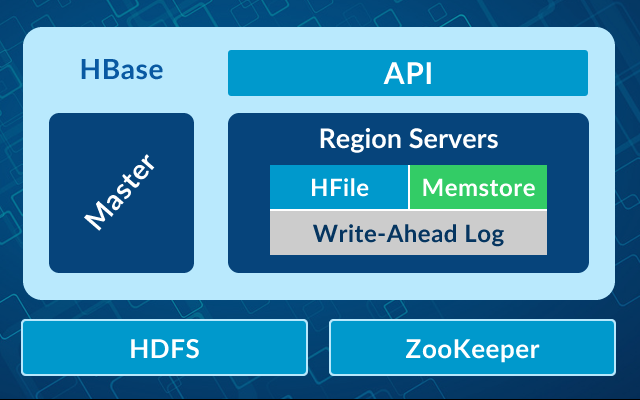
Hadoop HBase Components
There are three important components of Hadoop HBase which are:
HMaster
HMaster is known as “master server” in HBase. It is a lightweight process which is used to assign region server in the Hadoop cluster for load balancing. It manages the DDL operations on tables. HMaster monitors the region server. When a client wants to change the structure or want changes in metadata, all these things are done by the HMaster. For ensuring the highest degree of availability, a second HMaster is used.
Region Server
Regions are nothing HBase tables, divided horizontally by using row key and its purpose is to serve Region Server. Region Server is used to communicate with the client and manage all the data related operations. All the read and write requests from the client are handled by the Region Server. Size of the regions by limiting region threshold is also done by the Region Server.
Region Server also contains stores where memory and HFiles reside. Memstore is where initially all data is stored when they enter the HBase. After the processing, data is saved in HFiles in the form of Blocks, and Memstore is flushed.
Zookeeper
Zookeeper is an open source project used for the coordination and synchronization of distributed systems in clusters. Zookeeper assigns new regions in case of failure, and the recovery of any region server is done by loading them onto other region servers that are working properly. A client has to approach Zookeeper if he wants any kind of communication with the regions.
The client needs to access first Zookeeper quorum in order to establish a connection between Region Servers and HMaster and this only happens when the Region Servers and HMaster are registered with Zookeeper service. When the node failure happens in the cluster, Zookeeper quorum sends an error message and start repairing them.
Tracking of all the Region Servers which are running in the cluster is done by the Zookeeper. Zookeeper provides Ephemeral nodes which represent various Region Servers. HMaster uses ephemeral node for discovering available servers.
Bottom Line
To conclude, HBase is a non-relational database that is responsible to provide real-time access to the data in Hadoop. It is fast, fault-tolerant, and highly usable. And these characteristics makes it a best-fit for the storage of semi-structured data. It also allows applications or users that are integrated with HBase to access data very quickly.
Thus, HBase is the main component that is responsible for the effective Hadoop storage which in turn, increases the demand for Hadoop professionals. If you are an aspirant preparing for Hadoop administration certification, Best Big Data Online Course/s will help you reach your goal.