Table of Contents
Hadoop is an open-source Java-based framework. It was built on Java programming language and Linux Operating system. Hadoop is a tool used for big data processing and many companies are using Hadoop to maintain their large set of data.
Hadoop is the project of Apache Software Foundation. Hadoop has undergone a number of changes since the day it was launched. Before getting on how to install Hadoop let us know more about Apache Hadoop.
What is Apache Hadoop?
Apache Hadoop runs on Java and is an open source framework used to process and store a large amount of data on a huge cluster. Hadoop framework is composed of four main components:
- Hadoop Common
- Hadoop Distributed File System
- YARN
- MapReduce
Want to learn more about Hadoop Framework? Read our previous blog Introduction to Apache Hadoop!
Hadoop Cluster Modes
Installing Hadoop is not an easy task as the Hadoop cluster is very complex to set up. Hadoop Software can be installed and operated in three modes:
- Standalone Mode
- Pseudo-Distributed Mode
- Fully Distributed Mode
- Standalone Mode
It is the default mode in which Hadoop is configured on your system after downloading. In the standalone mode, the Hadoop is run on a single node as a single Java process. HDFS is not used in this mode; for input and output, local file system is used. This mode is useful for debugging purpose.
- Pseudo-Distributed Mode
The Pseudo-distributed mode involves distributed simulation of Hadoop on a single machine. In this mode, a number of multiple DataNodes and TaskTrackers are set up on a single machine. And various daemons run as a separate Java process on the single machine in pseudo-distributed cluster.
- Fully Distributed Mode
In the Fully Distributed Mode, the code can be run on the actual Hadoop Cluster. This mode allows you to run the code on thousands of servers, against very large inputs. All the Hadoop Daemons run on the master mode.
Install Hadoop Software
Now, after understanding Hadoop, it is the time to learn how to install Apache Hadoop. Let’s consider the installation of Hadoop on single node i.e. in Standalone mode. This will help you perform simple operations using MapReduce and HDFS. The followings are the steps are to install Hadoop 2.4.1 on Linux.
Prerequisites
- Operating System: Hadoop uses GNU/Linux clusters on 2000 nodes as it is supported by Linux as development and production platform. If you have any other operating system, install Virtualbox software and have Linux inside it.
- Java: As Hadoop is a Java-based framework, Java is the main prerequisite to install Hadoop. In order to run Hadoop on Linux, Java should be installed. Recommended versions of Java for Hadoop are available at Hadoop Java Versions.
- SSH: ssh must be installed in order to use the start and stop Hadoop scripts. sshd must be running in order to use them. Pshd must be installed for better sshd resource management.
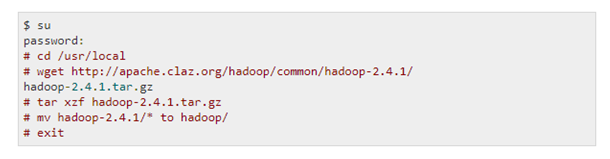
Download Hadoop
Download the Hadoop latest stable release from Apache Software Foundation. This is required in order to get the Hadoop Distribution. Use the following command to download and extract Apache Hadoop:
Install Hadoop in Standalone Mode
Once you have downloaded and extracted the Hadoop software, get prepared to set up the Hadoop cluster. You can start using it in any of the three modes. But by default, Hadoop cluster is configured to run on a non-distributed mode i.e. standalone mode. It runs as a single Java process which is useful for debugging.
Setting up Hadoop
-
- Set Hadoop environment variables by running the following command to ~/.bashrc file –
![]()
-
- Now, run the following command to ensure that Hadoop is running fine –
![]()
-
- You will receive the following output if you have successfully set up Hadoop –

Now, you are ready to work with the Hadoop in standalone mode on a single machine.
Bottom Line
Congratulations! You have successfully installed and setup Hadoop in Standalone mode. It’s the time to start working with Hadoop and use it to store, analyze, and process Big Data. Hadoop is one of the best big data processing tools, has gained popularity due to its significant features like fault–tolerance, scalability, flexibility, and cost-effectiveness.
Waiting for what? Start learning Hadoop now! Enter into the world of Big Data Hadoop and become a Hadoop professional.
Want to know more about Hadoop? Stay tuned and keep learning!