If you want to practice data structure and algorithm programs, you can go through Java coding interview questions.
In this post, we will see about Bellman ford algorithm in java.
Bellman Ford Algorithm is used to find shortest Distance of all Vertices from a given source vertex in a Directed Graph. Dijkstra Algorithm also serves the same purpose more efficiently but the Bellman-Ford Algorithm also works for Graphs with Negative weight edges. In addition to that, it also detects if there is any negative Cycle in the graphs.
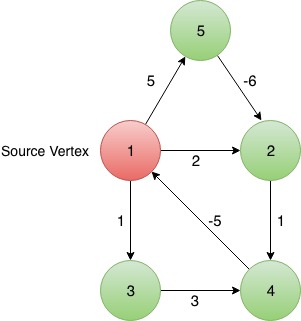
Input Format :
In the first line, given two space separated integers, that is, number of vertices(V) and edges(E).
Next E lines contains three integers each, which represents an edges from first integer to second integer with weight equal to third integer.
In the last line given an integer representing the source.
Output Format:
Output the shortest distance of every vertex from given source.
5 7
1 2 2
1 5 5
1 3 1
2 4 1
3 3 4
4 1 5
5 2 -6
1OUTPUT-1:
Distance of 1 from source is 0 and path followed is 1
Distance of 2 from source is -1 and path followed is 1->5->2
Distance of 3 from source is 1 and path followed is 1->3
Distance of 4 from source is 0 and path followed is 1->5->2->4
Distance of 5 from source is 5 and path followed is 1->5INPUT-2:
5 7
1 2 2
1 5 5
1 3 1
2 4 1
3 3 4
4 1 -5
5 2 -6
2OUTPUT-2:
Negative Cycle Detected
Algorithm:
Basically in this algorithm, we are looping in a random set of edges, vertices-1 times.
That random set can be any order of all the edges of the given graph.
- For every edge, E(u->v), we check if the current distance of v from source is greater than the distance of u and the weight of this edge combined, if it is, this means that we just found a better path with lesser distance than the previous path, and we update the distance of Vertex v from source to distance of u + weight of E(u->v).
- Say the random order of edges we will be processing is,
{(1,2), (1,3), (1,5), (2,4), (4,1), (3,4), (5,2)}
We first need to initialize the distance of all the vertices from source vertex to be Infinity except the source vertex itself, as it is 0 distance away from itself.
We need to maintain a HashMap for storing the nodes which contain, name of vertex, distance from source node, path of the shortest distance from source to this vertex. Vertex, Node will be the key value pair for the table.
Now initially our HashMap will be this,
vertex -> (vertex, distance, path)
1 -> (1, 0, 1)
2 -> (2, Infinity, ” “)
3 -> (3, Infinity, ” “)
4 -> (4, Infinity, ” “)
5 -> (5, Infinity, ” “) - Now we process this set of edges (V-1) times, that is, 4 times,
First iteration :
Here distance(x) represents shortest distance of vertex x from source node till that iteration.
edge(1->2), distance(2) > distance(1) + weight(1,2), distance(2) will be updated to 0 + 2 = 2 and the path of vertex 2 will now be, path of vertex 1 + "2", that is, 1->2
edge(1->3), distance(3) > distance(1) + weight(1,3), distance(3) will be updated to 0 + 1 = 1 and the path of vertex 3 will now be, path of vertex 1 + "3", that is, 1->3
edge(1->5), distance(5) > distance(1) + weight(1,5), distance(5) will be updated to 0 + 5 = 5
and the path of vertex 5 will now be, path of vertex 1 + "5", that is, 1->5
edge(2->4), distance(4) > distance(2) + weight(2,4), distance(4) will be updated to 2 + 1 = 3
and the path of vertex 4 will now be, path of vertex 2 + "4", that is, 1->2->4
edge(4->1), distance(1) < distance(4) + weight(4,1), distance(1) will not be updated and hence no updation in their path as well. edge(3->4), distance(4) < distance(3) + weight(3,4), distance(4) will not be updated and hence no updation in their path as well. edge(5->2), distance(2) > distance(5) + weight(5,2), distance(2) will be updated to 5+(-6)= -1 and the path of vertex 2 will now be, path of vertex 1 + "2", that is, 1->5->2.
Second iteration :
edge(1->2), distance(2) = distance(1) + weight(1,2), distance(2) will not be updated and hence no updation in their path as well.
edge(1->3), distance(3) = distance(1) + weight(1,3), distance(3) will not be updated and hence no updation in their path as well.
edge(2->4), distance(4) > distance(2) + weight(2,4), distance(4) will be updated to -1 + 1 = 0
and the path of vertex 4 will now be, path of vertex 2 + "4", that is, 1->5->2->4
edge(3->4), distance(4) < distance(3) + weight(3,4), distance(4) will not be updated and hence no updation in their path as well. edge(5->2), distance(2) = distance(5) + weight(5,2), distance(2) will not be updated and hence no updation in their path as well.
Third iteration :
No edge(u->v) will hold the condition distance(v)>distance(u)+weight(v, u).
Fourth and (vertices-1)th iteration :
No updation.
- After (Vertices – 1) iterations are done, we iterate the same list one more time to check if there is a negative cycle or not.
During this very last iteration, if there is updation in the shortest distance again, this means that there is definitely a negative cycle in the graph, and hence, the shortest distance of every vertex can not be calculated for this graph as we can keep looping again and again in that negative cycle to keep reducing our distance further. Thus, we print that the graph contains a negative cycle and return from the function.
We can clearly have the doubt of why do we need to iterate (vertices – 1) times, when we can achieve the shortest distance in less than (V-1) iterations.
The number of iterations it will take to find out the shortest distance for every vertex, completely depends on the random order in which we are processing our edges. Remember, I am emphasising on finding out shortest distance for calculating which in the worst case we need to iterate atleast (vertices – 1) times.
Lets see,
What if we had the order of the set starting with farthest(in terms of edges) from the source node, we would try to check if dist(2) > dist(5) + weight(2,5), but the correct distance of 5 isn’t calculated yet and it is still Infinity, so we do nothing, and now we move to second edge whose correct distance again isn’t calculated yet, so we do nothing again, so ultimately after this iteration end we will be able to update distance of only those vertices which are immediate neighbour of source.
To understand this more clearly, lets consider the worst possible random set of edges for this linear graph,

- Say the random order of edges we will be processing is,
{(1,2), (2,3), (3,4)}
Now in the first Iteration,
=> for (1,2), distance(1) > distance(2) + weight(1,2), therefore, distance(2) gets updated to 5 from Infinity.
=> for (2,3), distance(3) > distance(2) + weight(2,3), distance(3) is now 5+6 = 11.
=> for (3,4), distance(4) > distance(3) + weight(2,3), distance(3) is now 11+7 = 18.
We see that the shortest possible distance of all the vertices(2,3,4) from source(1) got calculated in just one iteration.
- Now lets consider a different Random order of edges,
{(3,4), (2,3), (1,2)}
In the first iteration, no updation will be seen for any edge except the immediate neighbour of source vertex, because while calculating the distance for vertex 4, distance of vertex 2 hasn’t been calculated yet. Same will be the case while calculating for vertex 3. Distance of a farther vertex can’t be calculated until we know the distance(doesn’t matter if it’s smallest or not) of closer vertex.
In second iteration, no updation will be there for vertex 4, as the distance of closer vertex 3 hasn’t been calculated yet. So updation will be seen for vertex 3 as we already calculated a distance of vertex 2 from source vertex.
And now in the third and (vertices-1)th iteration, we finally find the distance for vertex 4 because now we know the distance of vertex 3 from source vertex.
- There we see, number of iterations totally depends on the random order in which we process the edges, but in the worst random set of edges, we needed to iterate (V-1) times to completely calculate the shortest distance of all vertices from given source node. And hence we have our answer for the question, Why do we do this process for a random set of edges for Vertices-1 times?
Number of iterations = (Vertices – 1) + 1{one more iteration for detecting negative cycle}
= Vertices
and every time we are processing a set containing all of the Edges.
Therefore, the worst time Complexity for this algorithm will be O(V*E).
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 |
package Graphs; import java.util.HashMap; import java.util.Scanner; public class BellmanFord { public static class edge { int u; int v; public edge(int u, int v) { this.u = u; this.v = v; } public String toString() { return this.u + " " + this.v; } } public static class Node { int val; int dist; String path; public Node(int val, int dist, String path) { this.val = val; this.dist = dist; this.path = path; } public String toString() { return "Distance of " + this.val + " from source is " + this.dist + " and path followed is " + this.path; } } public static void main(String[] args) { Scanner scn = new Scanner(System.in); int nodes = scn.nextInt(); int[][] graph = new int[nodes + 1][nodes + 1]; int numEdges = scn.nextInt(); for (int edge = 0; edge < numEdges; edge++) { int u = scn.nextInt(), v = scn.nextInt(), w = scn.nextInt(); graph[u][v] = w; } bellmanford(scn.nextInt(), nodes, numEdges, graph); } public static edge[] getEdges(int numEdges, int[][] graph) { edge[] rv = new edge[numEdges]; int idx = 0; for (int u = 1; u < graph.length && idx < rv.length; u++) { for (int v = 1; v < graph[u].length && idx < rv.length; v++) { rv[idx] = new edge(u, v); idx = graph[u][v] != 0 ? idx + 1 : idx; } } return rv; } public static void bellmanford(int src, int nodes, int edges, int[][] graph) { /* * we use hashmap to store the nodes of every vertex, * (vertex name, node) will be the key, value pair */ HashMap<Integer, Node> nodesMap = new HashMap<>(); for (int i = 1; i < graph.length; i++) { /* * initialize the shortest distance of the every * vertex equal to Infinity as for this vertex * the shortest distance is yet to be calculated, * and initialize an empty path. But if the vertex * is source vertex itself, then the shortest distance * for it will be 0 and path will be initialized with * vertex name. */ nodesMap.put(i, new Node(i, i == src ? 0 : (int) 1e9 + 1, i == src ? Integer.toString(i) : "")); } /* outer loop will run for vertices - 1 times */ for (int var = 1; var <= nodes - 1; var++) { /* running inner loop on the set of edges returned * from getEdges function */ for (edge e : getEdges(edges, graph)) { Node u = nodesMap.get(e.u); Node v = nodesMap.get(e.v); /* * the basic condition for updation of shortest * distance of any node as mentioned in the above * discussion. */ if (v.dist > u.dist + graph[u.val][v.val]) { v.dist = u.dist + graph[u.val][v.val]; v.path = u.path + "->" + Integer.toString(v.val); } } } /* * one more loop in the random set of edges to detect if * there is any negative cycle or not */ for (edge e : getEdges(edges, graph)) { Node u = nodesMap.get(e.u); Node v = nodesMap.get(e.v); /* * if the we still are able to find shorted distance * this simply means that there is a negative cycle * for sure and hence we return from the function as * shortest distance for every vertex from source can * not be found for such graph as we can get even * shorter distance by looping once again in that * negative cycle. */ if (v.dist > u.dist + graph[u.val][v.val]) { System.out.println("Negative Cycle Detected"); return; } } for (int node : nodesMap.keySet()) { System.out.println(nodesMap.get(node)); } } } |
That’s all about Bellman ford algorithm in java.
good website very helpful